AWS Glue の概要
AWS Glue を一言でいうと、ETL のマネージドサービスです。
ETL でデータを取得する先のデータベーススキーマを管理する機能や、ETL のジョブをサーバレスで実行する機能などを持ちます。
全体像
Glue に登場する主な概念は以下のようになります。
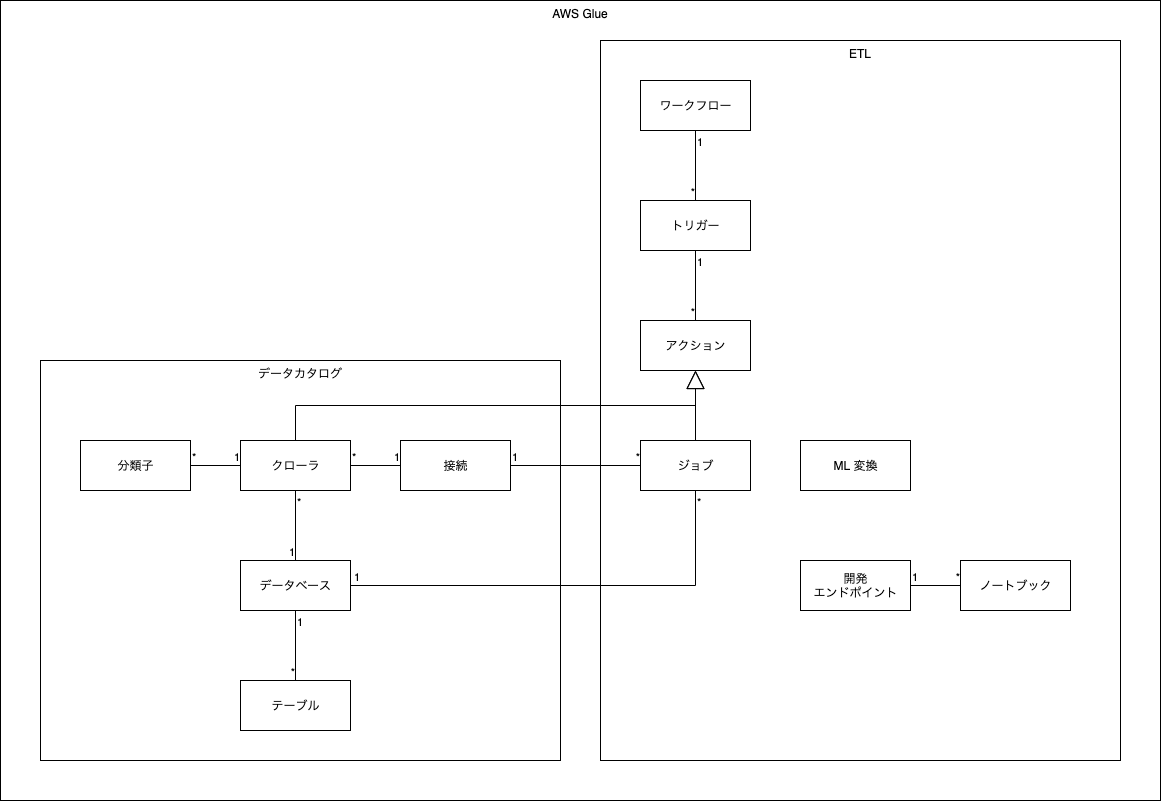
2020/7/10 時点で Glue のマネジメントコンソール上のメニューは「データカタログ」と「ETL」の 2 つに分類されています。
Glue の使い方の概要が分かるよう、「データカタログ」と「ETL」のそれぞれについて説明していきます。
データカタログ
まずは「データカタログ」に分類される、データベーススキーマの管理に関する機能です。
データベース・テーブル
ETL の入力となるデータベースのスキーマを管理する機能です。
API などを使って手動で登録することもできますし、後述するクローラを使って自動で登録することもできます。
接続

データベースの接続設定 (JDBC の URL やユーザ名・パスワード) です。
Glue の機能でデータベーススキーマを自動取得 (クローリング) したり、ETL 処理を実行する際に使います。
クローラ・分類子
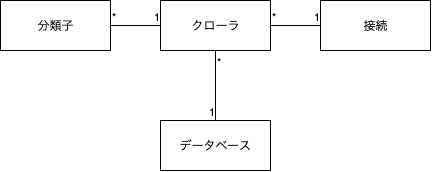
クローラを使うことで、データベースをクローリングし、スキーマを自動で取得することが可能です。
分類子は、クローラがスキーマを認識する方法の設定みたいなものです。
クローラを使って自動でスキーマを登録することで、スキーマが変わった際に追従するのも楽になります。
後述するトリガーによって定期的にクローリングすることも可能です。
ETL
続いて、「ETL」に分類される、実際の ETL 処理に関する機能です。
ジョブ
ETL の処理です。
Glue は Python のスクリプトや Spark などの実行環境を選べるので、その実行環境で実行するコードを指定してジョブを作成します。
トリガー

クローラやジョブを定期実行したりする際に使うのがトリガーです。
トリガーの発火条件として他のトリガーやジョブを指定することもできます。
ワークフロー
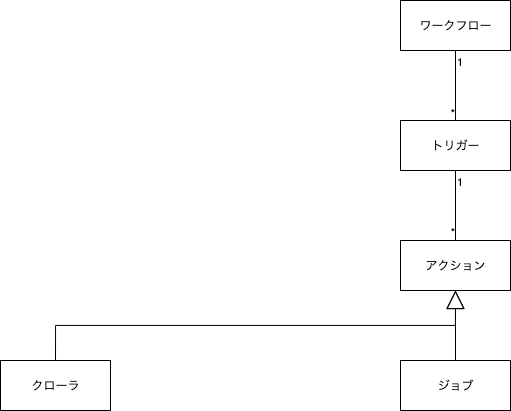
ワークフローを使うと、トリガーやジョブを複雑に組み合わせた ETL 処理を可視化したりできます。
ML 変換

データの前処理として必要な変換を機械学習で実行する機能です。
開発エンドポイント・ノートブック

Glue のジョブは実行待ち時間があったりするため、スクリプトを開発するのが結構大変です。
スクリプトの実装を楽するための設定が開発エンドポイントです。
開発エンドポイントにはローカルや VPC に起動した Jupyter などを接続することも可能ですが、Sagemaker のノートブックと連携する機能も用意されています。
開発エンドポイントは料金が結構高いので、作成したまま放置しないようご注意ください。
ローカルに完結したスクリプト実装も可能なようなので、試してみるとよさそうです。
参考
おわりに
私が初めて Glue を使おうとしたときは、思っていたより多機能で、どこから着手したものかと思いました。
雰囲気が分かると意外と簡単に使えたりするので、是非さわってみてください。
開発エンドポイントという機能がありはするものの、自動テストなどによるコードの動作保証にはなかなか苦労すると思います。
スクリプトの自動テストや CI / CD は工夫しがいがあって面白いかもしれません。
参考
Web
書籍
2020 年 7 月に発売された書籍『AWSではじめるデータレイク: クラウドによる統合型データリポジトリ構築入門』では、Glue を ETL として利用する典型的な例や、Glue のデータカタログを Athena で利用する例が画面キャプチャ付きで丁寧に解説されてます。 データレイクに限らず、データウェアハウスや BI なども含めた AWS でのデータ分析について幅広く学べる非常におすすめの書籍です。




